

Across most industries this year, leaders in all functions are working through difficult prioritization and budget justification exercises. Spending that was previously approved with minimal scrutiny is now being put under the microscope by finance and procurement teams.
Software engineering organizations aren’t exempt from these intense audits, but development teams still have products to ship and expectations to meet. Now they’re attempting to pull it off with more limited resources.
Let’s take a look at four approaches for navigating software engineering orgs through this lower-spend environment.
1. Don’t let critical services get orphaned
Service Ownership is always important; orphaned or neglected services will eventually cause outages and reliability headaches even in good times.
But when org charts change rapidly and developer turnover is high, services are more likely to get lost in the shuffle. A microservice catalog that’s designed to keep up with these shifting relationships prevents any service or system from being overlooked.
Avoiding a potential crisis by keeping ownership well organized through a reorg is a great first step. But Service Ownership has more to offer.
In addition to explicit ownership (team X owns service Y), Service Ownership also includes clear expectations and guidance about what maintenance or operational activities service owners are responsible for.
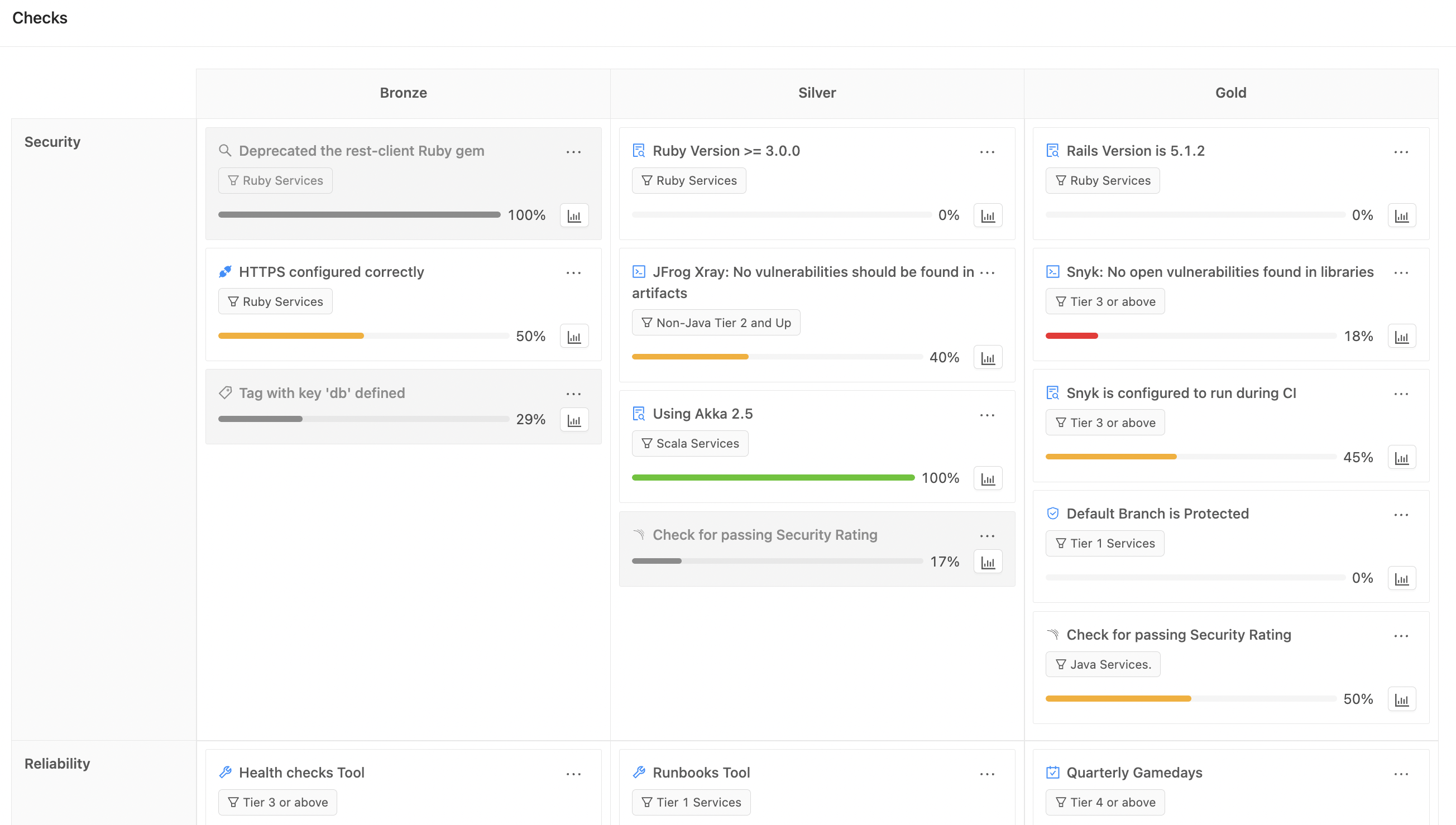
When engineering time and resources are limited, Service Ownership enables developers to spend less time:
- tracking down service ownership, metadata, and documentation
- figuring out if an operational task is urgent (or even relevant)
- determining how to best accomplish a task
This allows more time for core product development work that can drive the business forward.
2. Stop relying on tribal knowledge.
Whatever you like to call it–tribal, implicit, or institutional knowledge–every organization faces this challenge. Valuable information about internal systems and processes lives primarily in the heads of the longest-tenured or most experienced employees.
When those critical employees leave an organization (or even change teams), that valuable info leaves with them.
Worse, the situation is especially common outside the happy path: troubleshooting, workarounds, exceptions, and edge cases. Reorgs and employee turnover are challenging, but if your organization is reliant on tribal knowledge, they can be very disruptive.
The solution? Continuously document everything important about your architecture with a centralized, automated tool.
The outcome? Reduced cognitive load on all engineers–before, during, and after any spikes in turnover or changes in team membership.
3. Assess and triage tool sprawl
When software teams are asked to reevaluate their spending, budgets for tooling are often the first area of investigation.
Over time, it’s common for larger teams to wind up with a significant level of inefficient, redundant, or ineffective tooling spend. This happens organically in a variety of ways:
- mergers and acquisitions that create tool redundancy or overlap
- bottoms-up adoption of different tooling by different teams
- the expansion of the tools themselves as they add new capabilities
Of course, OpsLevel isn’t exempt from these budget reviews and we want to earn our customer’s business.
Fortunately, we believe that managing tool sprawl–and trimming spend when necessary–is a clear OpsLevel capability and use case.
With our catalog, OpsLevel shines a light on which services (and owning teams) are using which tools within your DevOps toolchain.
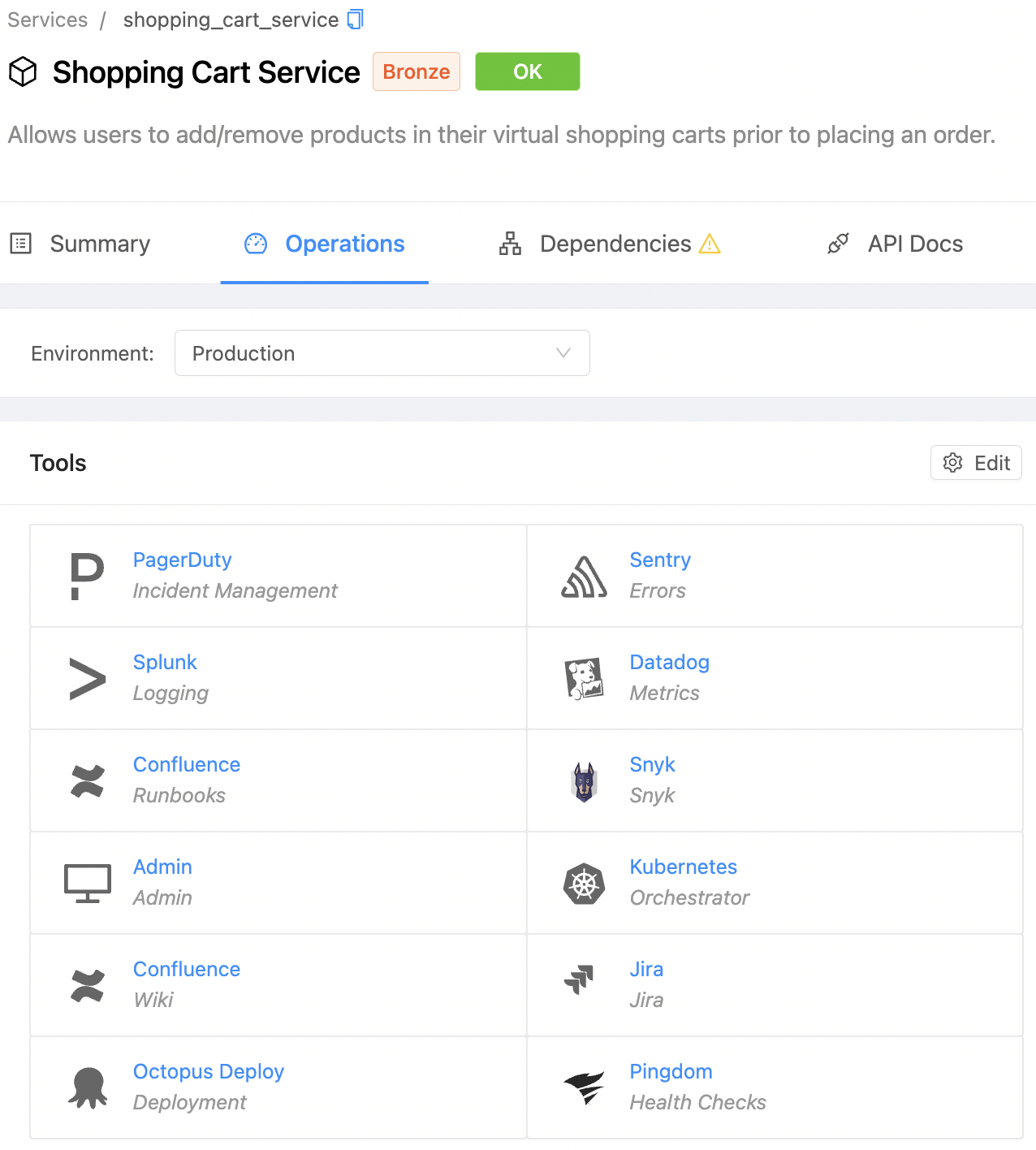
If your catalog has gaps, we enable central SRE, platform, or security teams to close them. With automated, scalable checks and campaigns service owners have incentives to and mechanisms for clearly documenting their services’ toolchains.
With a comprehensive catalog, spending reviews and decisions can be conducted and made more confidently.
And if one of the outcomes is swapping out or consolidating pieces of your toolchain within your organization, OpsLevel can drive this change as well.
4. Unlock lasting efficiency through standardization
Any list of ideas for doing more with less includes standardization.
The underlying principles are that standardization cuts out:
- unnecessary decision points for builders–e.g. which Ruby gem should I use here
- unnecessary education of future maintainers–e.g. what’re the differences between two Ruby gems that are similar, but not exact, substitutes for one another
Individual examples of standardization don’t always appear to be that impactful. But when you consider standardization programs in aggregate–eliminating a broad variety of decision points across your tech stack–the benefits become more obvious.
Implementing standardization that makes an entire software engineering organization more efficient is no small feat though. A program like this needs mechanisms for:
- Identifying the status quo of architectures and configurations
- Documenting and prioritizing an organization’s preferred standards
- Driving adoption of standards through awareness and education campaigns
- Continuously monitoring that preferred standards are followed by service owners
Like almost anything else, standardization is best viewed as a spectrum, not a binary choice. OpsLevel helps software teams find and maintain balance at the right point on the spectrum.
Looking Forward
Shifting your software engineering department towards leaner operations isn’t easy and won’t happen overnight. But the principles outlined above can serve as clear starting points.
If you’re looking for a trusted partner who can help you put them into practice with software, get in touch today.

.png)

Subscribe
Join our newsletter to stay up to date on features and releases.
By subscribing you agree to with our Privacy Policy and provide consent to receive updates from our company.

