

With services, proper reliability is critical to success. But many don’t fully understand what reliability entails. In this post, we’ll set you up for success with an essential guide to understanding and improving service reliability.
Let’s get started by defining reliability.
What Is Service Reliability?
We’ve heard of many “ilities” when it comes to software: availability, scalability, usability, maintainability, and more. All provide value. And to improve those “ilities,” we must understand them. So let’s break reliability down and see what it’s made of.
Reliability encompasses multiple facets that together provide a usable and dependable product for the customer. Why the customer? Because reliability focuses on their experience with your service. And metrics and measures that don’t talk about the customer experience miss the mark on understanding reliability.
Why does the customer experience tie to reliability? If our service has an uptime of 99.999% over a time period but the customer experiences excessive latency or flaky behavior, the service lacks reliability. Alternatively, if a large percentage of back-end services are down but the customer is unaware because of mitigations, then the service is still reliable.
To understand that further, let’s break down the multiple facets of reliability into smaller chunks. Therefore, I’m going to refer to how reliability is defined through the eyes of quality metrics in manufacturing and engineering.
Reliability encompasses multiple facets that together provide a usable and dependable product for the customer.
According to the American Society for Quality, reliability represents the probability that a service will perform its intended function for a period of time. Furthermore, reliability consists of:
- Probability of success
- Durability
- Dependability
- Availability to perform a function
- Quality over time
Let’s break these down into software engineering concepts.
Breaking Down the Components of Reliability
In this section, we’ll review the components listed above so you can begin to think about how these affect your service reliability. And remember, it’s always about the user or consumer perspective when understanding reliability.
Probability of Success
First, let’s discuss the probability of success. In your service, consider the percentage of successful requests versus unsuccessful requests.
For example, let’s say we’re looking at a back-end REST service. What makes a request successful or unsuccessful? Obviously, if server errors occur (HTTP status in the 500s), then we have an unsuccessful request.
But should you consider client errors? In a healthy system, client errors like Bad Request (400) or Unauthorized (401) should not go against your service success metrics. In this case, a client has caused an error.
However, what if a bug in your system causes excessive and inaccurate client errors? Or perhaps a change in your API contract increases the likelihood of client errors? These do affect your service reliability from the consumer’s standpoint.
Durability
Next, durability revolves around the recovery of your system, your service, or a transaction. When something goes wrong, can the system recover in a way that allows the customer to move forward? When the database fails, is the data in a state where the customer can pick up where they left off? Or is it in a corrupted state that requires either manual rework or manual data cleanup? If an instance of your service goes down, can the traffic reroute to another instance automatically?
In software, things go wrong. Can your service handle that?
Dependability
With good dependability, your product or service works as the customer expects. It provides them the value that you advertised or promised. And it meets your service-level agreements (SLAs).
This one can’t always easily be monitored, but using customer interviews, reviews, or quality indexes can help. Also, metrics that show customers leaving the product over time may indicate that your service does not provide the dependability needed.
Availability
Next let’s talk about the availability, or uptime, of your service.
Availability vs. Reliability
Oftentimes people confuse or equate availability and reliability. However, availability is only one part of the entire reliability picture.
Why do we need to consider more than availability? Consider the case where a service has high availability but a low probability of success. To the customer, the service still lacks reliability even though the service has great uptime. Also, consider how many customers are affected by a service’s errors or downtime. If only a tiny percentage of customers see the effects of downtime, that’s different than a large number of customers feeling those effects.
So, if adequate redundancies or mitigations exist that improve reliability to the consumer due to issues with availability, then reliability can still be good. To expand further, if a service is down in one region or is operating at half capacity with half the instances down, but 99% of customer transactions still make it through, the overall reliability could still meet needs.
Again, reliability must focus on the customer’s experience with the service as a whole, and not just one internal metric.
Measuring Availability
In software terms, you’ll hear that a service is available at three nines (99.9%) or five nines (99.999%) over one month.
We calculate availability by taking uptime and dividing it by the sum of uptime and downtime. And typically we measure this over a consistent period like a month or quarter.
When measuring uptime and setting goals, remember that you should not give every service a blanket target. Each service has a different use and may have different availability needs.
Quality Over Time
And finally, let’s talk about quality over time. I use this bullet to aggregate and understand how reliability and the customer experience change over time. Do these things get better or worse over time? Are there systemic issues that resulted in those changes? And how do we either improve or keep them flat? This varies from service to service.
For all metrics, changes over time, even slow ones, can indicate a condition that needs attention.
Improving Service Reliability
Now that we have an understanding of service reliability, let’s get started on improving it.
Assess Your Current State
In order to understand where to go, you must figure out where you’re starting from.
First, start with the customer or end user. Without understanding that customer experience, you may find yourself improving parts of the system that don’t matter. What’s critical for your customer and what’s irrelevant? How does the latency of your system affect the job they’re trying to do? And what level of reliability do they need?
If your service provides a mission-critical function, you’ll need to have better reliability than if your system provides nice-to-have features or similar.
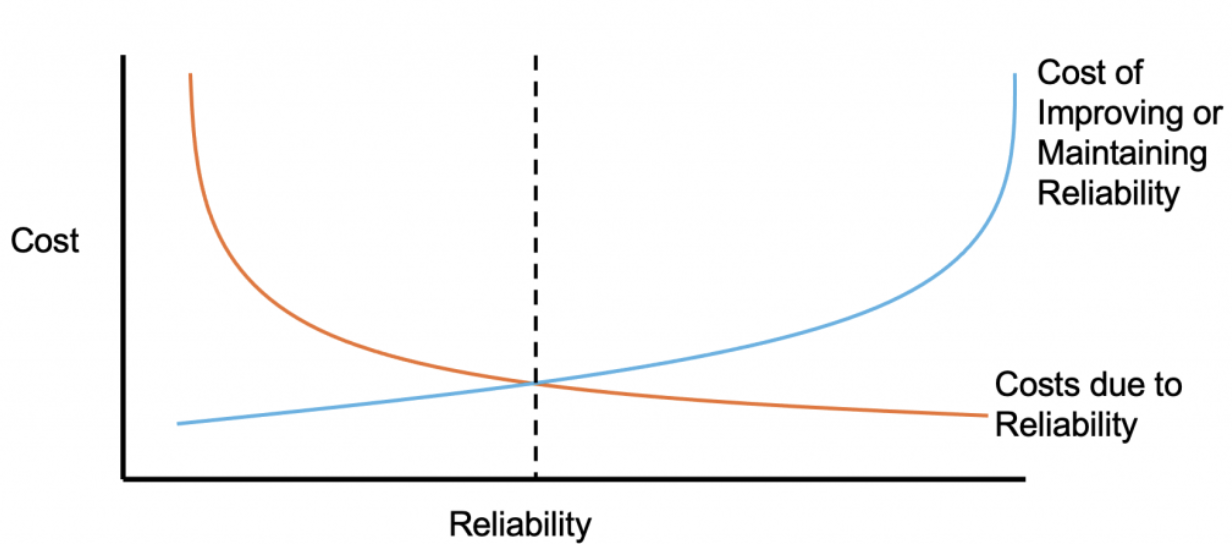
At this point, you’ll begin to understand what poor reliability costs. You may be tempted to continually improve reliability forever. However, remember that improving reliability costs time and money. So you want to only improve your reliability to the level needed for your customers, and not beyond.
Next, start measuring and gathering basic system metrics. What’s your service availability? How many of your transactions or calls are successful? What is your latency for critical functions? Evaluate these with an eye towards the customer experience, and that will give you a place to begin your reliability improvements if they’re needed.
And finally, look at the processes, both manual and automated, that contribute to your reliability costs. Do support folks continually answer similar questions or correct data? Are there automated data cleanup jobs? What’s the engineering support load look like? Do engineers have to investigate data irregularities or outages frequently? You may find items that will improve the quality and functionality of the service by systematically assessing your current state.
Invest in Improvements to Reliability
Once you understand the areas where your service does well and where it needs to improve, consider the following corrections or safeguards to improve reliability.
Testing Reliability
With testing, automation receives priority. Whether it’s enhancing your unit, integration, or end-to-end tests, make sure tests are fast, repeatable, and part of your continuous integration process. This can improve reliability quickly. But don’t forget about manual exploratory testing from time to time. Customers can use systems in unexpected ways or flows, which can be found through exploratory testing.
Monitoring Reliability
As part of assessing your current state, you may already have monitors in place to track the health of your system. Don’t assume that these monitors are static. Review them periodically and modify, enhance, or even delete them based on your particular needs.
Reliability Metrics
While monitoring often covers system metrics, you’ll also want to consider reliability metrics. For example, how many customers were affected by an outage? How many stop using your service? Has the number of transactions in one part of the service dropped, indicating a potential issue upstream or a missed business situation?
Dependencies and Reliability
Next, what if your availability is affected by your service dependencies? Yes, it’s true that they will have to improve, but also what can you do so that your service is durable and resilient to downstream failures? Can you add caching or automated workarounds? Or can you add fallbacks that don’t provide full functionality but ensure that critical functions continue?
Organizational Visibility
And lastly, visibility. With service reliability metrics, make sure they’re visible to the organization through service maturity metrics. Knowing the reliability metrics of both your upstream and downstream services will affect system design and mitigations. So make that data known early on and often.
Summary
In this post, we covered what reliability means, how you can assess our current reliability, and how you can take meaningful strides to improve it. Once you’ve made progress, you’ll want to solidify and share best practices for your organization. Also, consider how we can improve the visibility of your service reliability across your organization by requesting a demo today.
This post was written by Sylvia Fronczak. Sylvia is a software developer that has worked in various industries with various software methodologies. She’s currently focused on design practices that the whole team can own, understand, and evolve over time.
.webp)

.png)
Subscribe
Join our newsletter to stay up to date on features and releases.
By subscribing you agree to with our Privacy Policy and provide consent to receive updates from our company.

